
A Comparative Analysis of Sales Prediction Models: PHP-ML’s SVR vs. Python’s SVR & Linear Regression
Background
I, Sayem Iftekar, have performed this research for my postgraduate degree, and it has been approved and selected by one of the prestigious journals, IJCA (International Journal of Computer Applications), ISSN 0975-8887.
With a passion for exploring innovative solutions to real-world challenges, my research endeavours focus on enhancing predictive analytic capabilities, particularly in sales prediction, through rigorous comparative analysis and practical implementations. Academic background and professional experience reflect my deep commitment to advancing the discourse on machine learning applications in business forecasting.
Introduction
In today’s data-driven business landscape, accurate sales prediction models are essential for informed decision-making. This blog is inspired by my research paper, which delves into a comprehensive exploration of sales forecasting, comparing the effectiveness of Support Vector Regression (SVR) models implemented using PHP-ML and Python libraries. By rigorously analysing performance metrics, I aim to provide valuable insights into the practicality and accuracy of these models, aiding decision-makers in selecting the most suitable solution for their predictive analytic needs.
Motivation
While Python dominates the field of machine learning, PHP-ML offers an intriguing alternative within the PHP ecosystem. This study aims to bridge the gap between PHP and Python by comparing their respective SVR implementations. By understanding the strengths and limitations of PHP-ML’s SVR for sales predictions, I aim to provide insights that assist organisations in making informed decisions regarding their machine learning endeavours.
Goal
My goal is to conduct a comparative analysis of SVR models implemented using PHP-ML and Python libraries. I will evaluate their performance and accuracy metrics to assess the practicality of PHP-based machine learning solutions for business forecasting. By comparing accuracy, efficiency, and applicability, I aim to provide valuable guidance for decision-makers navigating predictive analytics complexities.
Methodology
The study utilises historical sales data and implements SVR models using PHP-ML and Python libraries. Data pre-processing, model training, and evaluation are conducted systematically, considering metrics such as Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE). The comparative analysis aims to identify the most accurate and reliable model for predicting future sales, with practical implications discussed for integrating the chosen model into ERP systems.
Sales Prediction Dataset and Format
The model uses the historical data that is kept in an SQLite database as input. Despite being a lightweight relational database management system, it can manage massive data volumes and has a small binary footprint, low disc space use, and little runtime configuration. It can manage databases up to 2 terabytes in size and is portable between systems and networks. It saves data methodically in tables, rows, and columns within a single file.
Two datasets have been used for the technical experiment of the research – one from Kaggle that includes data on ‘supermarket sales’, with a sales pattern of regular ups and downs, and another that includes dummy data showing steadily rising trends. The same type of data and feature set were utilised to train the models and forecast the number of sales for five years, from the last available years dataset.
Sales Pattern Based On The Kaggle ‘Supermarket Sales’ Dataset’s Historical Data:
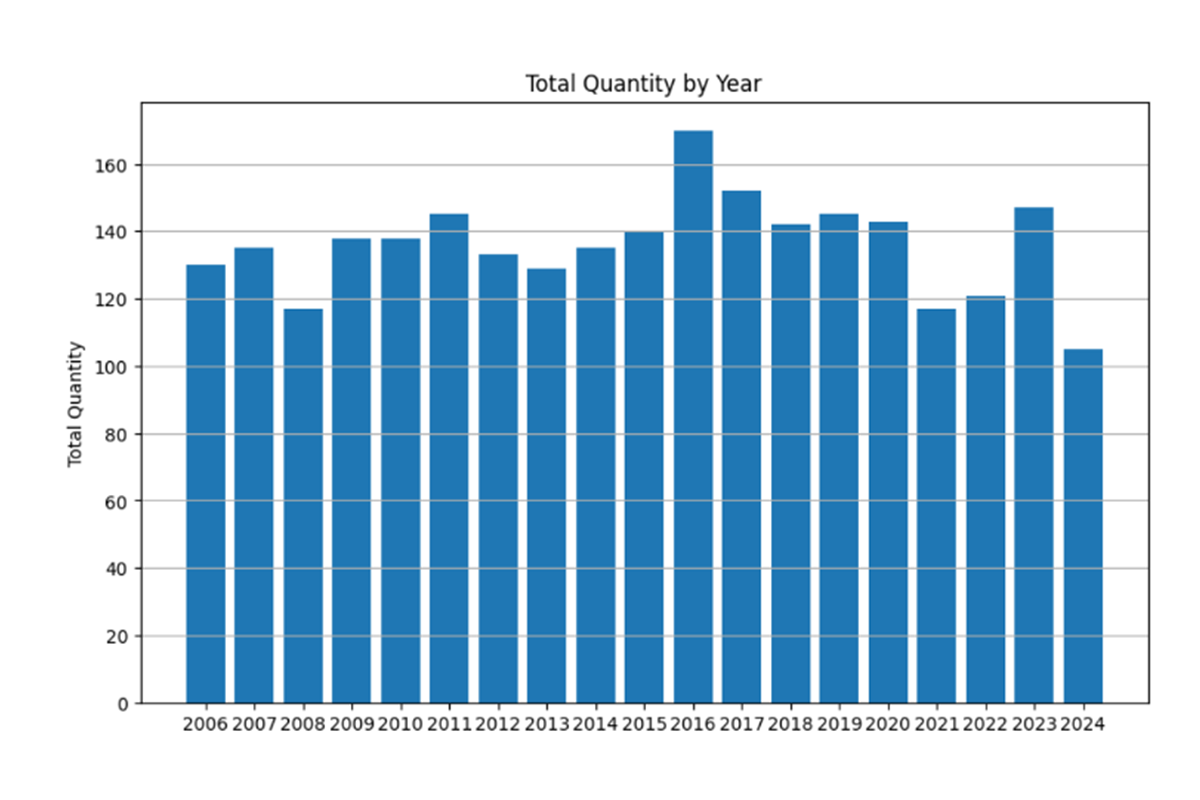
Sales Pattern Based On The Dummy Dataset’s Historical Data:
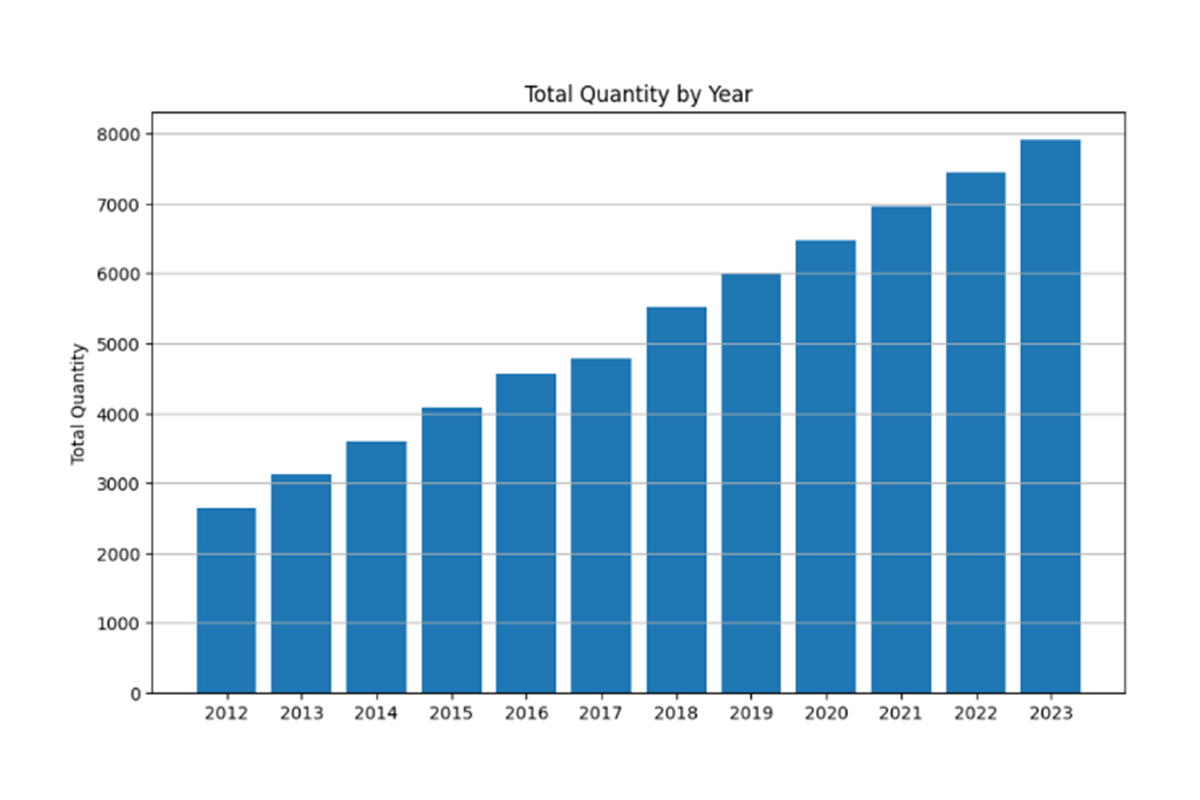
Experiments and Results
Through experimentation with both PHP-ML and Python implementations, I observed slight variations in accuracy metrics. While PHP-ML’s SVR model showed promising results, Python’s implementations also demonstrated strong performance. Factors such as data pre-processing methods, underlying algorithm implementations, and random seed initialisation influenced the model’s accuracy. However, PHP-ML’s SVR consistently exhibited lower MAE and RMSE scores, indicating its potential as a reliable solution for sales predictions.
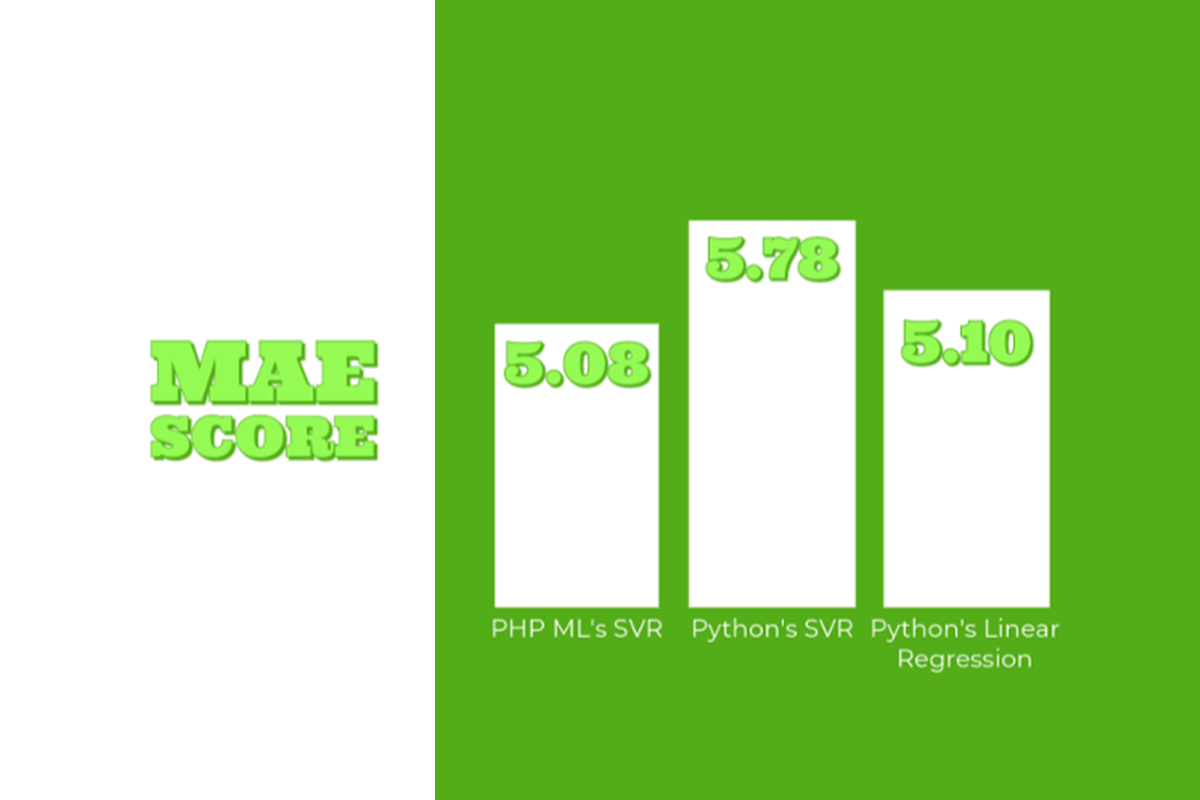
MAE Score
More detailed, accurate, and large-scale data sets increase accuracy. The MAE score for PHP-ML’s SVR model is 5.08, compared to 5.78 for Python’s SVR implementation, which is roughly 13.78% difference, and 5.10 for Python’s Linear Regression implementation, or 0.39% difference, in comparison to PHP-ML’s SVR. A 99 R2 score suggests that the independent variables account for 99% of the variation in the dependent variable, indicating a well-fitting and highly predictable model. However, it may also indicate overfitting, which could have an impact on the model’s performance when additional data is incorporated.
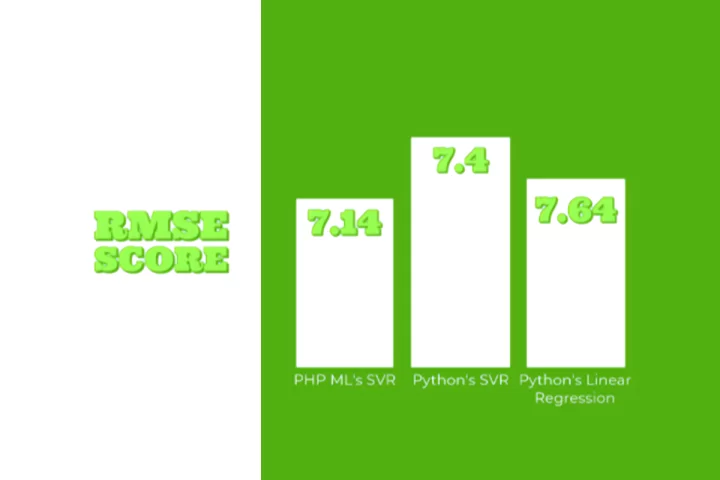
RMSE Score
A model’s ability to predict quantitative data is gauged by its Root Mean Square Error (RMSE), where lower values denote a better match. Among the three models, PHP-ML’s Support Vector Regression’s RMSE score is the lowest, which is 7.14. The model’s coefficient of determination (R2), which must be computed independently, is not directly measured by RMSE values. Furthermore, it should be noted that a lower RMSE does not always indicate a better model because interpretation of these values depends heavily on context and domain knowledge.
How Sales Prediction Accuracy is Measured
Sales prediction accuracy is a critical aspect evaluated meticulously by my research endeavours. The accuracy of sales predictions is typically measured using several key metrics, with Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) being among the most commonly utilised.
MAE quantifies the average absolute difference between predicted and actual sales quantities, providing a straightforward measure of prediction accuracy. On the other hand, RMSE calculates the square root of the average of the squared differences between predicted and actual sales quantities, offering a more comprehensive assessment of prediction errors while penalising larger deviations more heavily.
By analysing these metrics across different machine learning models and datasets, I gained valuable insights into the effectiveness of predictive models in capturing the underlying patterns and trends in sales data. These accuracy measurements serve as crucial indicators guiding the selection and refinement of machine learning algorithms for sale predictions, ultimately contributing to more informed decision-making processes in business forecasting.
Verge
Despite maintaining the same model construction, parameter settings, feature selection, and dataset, the two languages and libraries identical machine learning algorithms showed varying degrees of accuracy.
The MAE scores for support vector regression using the Python support vector regression library and the PHP-ML library may differ for several other reasons. I am comparing only the SVR models as they are utilising the same algorithm which is kind of apple-to-apple comparison.
The Following Are Some Variables That Might Have An Impact On The Outcome:
The SVR algorithm’s implementation specifics in every library.
Various optimisation techniques, numerical precision, and default values for some user-omitted parameters may be used by different libraries. For instance, the Python library makes use of the scikit-learn package, whereas the PHP-ML library leverages the LIBSVM library inside. The SVR problem may be solved differently by these two libraries, which might produce different results.
The steps for feature scaling and data pre-processing.
Proper pre-processing and scaling of the data is crucial before using SVR, as this can impact the model’s accuracy and performance. The manner that various libraries handle categorical variables, missing data, outliers, and normalisation may vary. For instance, the Python library can automatically scale the data if the option scale is set to ‘True’, but the PHP-ML library requires the user to explicitly scale the data using the StandardScaler class. These variations may lead to various SVR model input values, which may have an impact on the MAE and RMSE scores.
The SVR model’s random seed or initialisation of the SVR model.
Being a stochastic algorithm, SVR executes with a certain amount of randomness. The process of optimisation, support vector selection, or model parameter initialisation can all contribute to this randomness. Distinct libraries might employ varying random seeds or initialisation techniques, potentially yielding disparate outcomes. Setting the random seed or initialisation process to a fixed value in both libraries and comparing the results using the same seed or method is advised to assure reproducibility.
PHP-ML’s implementation of ‘Random Shuffling’.
Another explanation would be that PHP-ML’s implementation of ‘Random Shuffling’ lacks a library similar to scikit-learn, making it impossible to apply by default. This makes programming challenging because coding is required. When the shuffle option is not used, the train_test_split function from scikit-learn shuffles the data by default. This indicates that before dividing the data into training and testing sets, the function will shuffle it at random.
To compare the parameters and steps in the SVR process and identify the exact reason for the variation in the MAE and RMSE scores, a comprehensive review of the documentation and code for each library was carried out.
Conclusion
In conclusion, my comparative analysis highlights the nuanced differences between PHP-ML and Python implementations of SVR models for sale predictions. Despite variations in accuracy metrics, PHP-ML’s SVR emerges as a promising alternative, offering competitive performance in predicting future sales.
However, careful consideration of factors such as data pre-processing and algorithm implementation is crucial for achieving optimal results.
Ultimately, this study provides valuable insights for organisations seeking to leverage machine learning for enhanced business forecasting, and guiding informed decision-making in selecting suitable predictive analytic solutions.


